I need to create an A-Z index for a given list of terms appearing 1:N times inside an XML document. The terms inside the content can be marked through the application using a class or dedicated IDs. What is the general approach for generating an index in such a context? Is there something where the Javascript engine of PrinceXML 8 could help?
Forum › How do I...?
Index generation (using PrinceXML 8)
Yes, you could use JavaScript to scan through the DOM looking for elements with a particular class, then create links in the invoice to those elements. The script could also add IDs to the elements if they don't already have them.
mikeday wrote:
Yes, you could use JavaScript to scan through the DOM looking for elements with a particular class, then create links in the invoice to those elements. The script could also add IDs to the elements if they don't already have them.
hm....I know that it is similar to creating a table of contents....but how should the CSS Style look like for something like
Index
----
My Term.....20, 42, 98
<a id="my-term-1" class="term-my-term">My Term</a>
........
<a id="my-term-2" class="term-my-term">My Term</a>
.......
?
<a id="my-term-3" class="term-my-term">My Term</a>
The basic question remains:
Assuming that I have references to a term pages 10, 11, 12 and multiple references on page 40....could I collapse them somehow
into pages "10-12, 40" using the Javascript engine? I think I can't.
Assuming that I have references to a term pages 10, 11, 12 and multiple references on page 40....could I collapse them somehow
into pages "10-12, 40" using the Javascript engine? I think I can't.
We do have a creative hack for doing this with JavaScript in the final release of Prince 8.0. 
Sounds promising. Meanwhile I have a blueprint for getting around the limitations by generating the index part as dedicated PDF document and merging it later with the "content" PDF.
I thought "this sounds fun." I was right.
- The fat man
<html><head><title>Lulz</title><script type="text/javascript">
function CollapseToRangeString(PageNumbers, /* optional */ Between, /* optional */ Betwixt) {
if (typeof(PageNumbers) !== 'object') { return 'error: must be array'; }
var ContainerCapIndex = PageNumbers.length;
if (ContainerCapIndex < 1) { return ''; }
if (ContainerCapIndex == 1) { return PageNumbers[0].toString(); }
if (Between === undefined) { Between = '\u202f..\u202f' ; } // that's one third width mongolian non-breaking space
if (Betwixt === undefined) { Betwixt = ',\u2002' ; } // nut, aka breaking en-width space
var BaseIndex = PageNumbers[0];
var LastIndex = PageNumbers[0];
var i;
var RangeString = '';
var First = true;
for (i=1; i<ContainerCapIndex; ++i) {
if (PageNumbers[i] == (LastIndex + 1)) { ++LastIndex; }
else {
if (!First) { RangeString += Betwixt; }
RangeString += ((BaseIndex == LastIndex)? LastIndex.toString() : (BaseIndex.toString() + Between + LastIndex.toString()) );
BaseIndex = LastIndex = PageNumbers[i];
First = false;
}
}
RangeString = RangeString + ((First)? '' : Betwixt) + ((BaseIndex == LastIndex)? LastIndex.toString() : (BaseIndex.toString() + Between + LastIndex.toString()) );
return RangeString;
}
function BuildTestTable(ContainerId, Rows) {
var Container = document.getElementById(ContainerId);
var Table = document.createElement('table');
Table.className = 'TestTable';
Container.appendChild(Table);
for (i in Rows) {
var TR = document.createElement('tr');
var ShowCol = document.createElement('td');
ShowCol.style.color = '#444';
ShowCol.style.fontFamily = 'consolas, monospace';
ShowCol.style.textAlign = 'right';
var ToCol = document.createElement('td');
ToCol.style.color = '#06f';
ToCol.appendChild(document.createTextNode('\u21e2')); // ok so I have bad taste
var DoCol = document.createElement('td');
var First = true;
var ShowText = '';
for (j in Rows[i]) {
ShowText = ShowText + ((First)? '' : ',') + Rows[i][j].toString();
First = false;
}
ShowCol.appendChild(document.createTextNode( '[' + ShowText + ']' ));
DoCol.appendChild(document.createTextNode( CollapseToRangeString(Rows[i]) ));
TR.appendChild(ShowCol);
TR.appendChild(ToCol);
TR.appendChild(DoCol);
Table.appendChild(TR);
}
}
</script></head><body onload="BuildTestTable('TableContainer', [ [1,2,3], [1,2,3,4,5], [1], [1,2], [], [1,3], [1,2,4,5], [1,2,4,5,7,8], [1,4,5,8] ]);">
<div id="TableContainer"></div>
</body></html>- The fat man
John Haugeland is http://fullof.bs/
Oh snap, it should sort the array before it starts, to guard against stupid. Sorry.
Add as the very first line of the function PageNumbers.sort();
Add as the very first line of the function PageNumbers.sort();
John Haugeland is http://fullof.bs/
Quick notes: Unicode character escapes don't work in 8.0 beta, but will work in the final release, out soon. Also, setting the "style" property won't do anything, it isn't supported yet. Maybe in 9.0.
mikeday wrote:
Quick notes: Unicode character escapes don't work in 8.0 beta
Well, that sucks, as my editor isn't unicode aware.
mikeday wrote:
Also, setting the "style" property won't do anything, it isn't supported yet. Maybe in 9.0.
Whoa, whoa, whoa. This is a big, serious omission.
Is .className at least supported? I can make do without script-time CSS in the short term, but that's a very serious problem.
Why would this be omitted? This seems like it should be just a property mapping. Not having access to .style.whatever makes the graphing library which was the whole reason I just bought Prince useless.
John Haugeland is http://fullof.bs/
The .className property is supported, and you can set the style attribute using DOM calls, we just don't map it automatically to the style property yet. We can expedite this feature, as I do realise many scripts depend upon it.
I would really appreciate it if .style.foo got into 8. Protovis/d3 are dependant on it.
Thanks for considering the possibility.
Thanks for considering the possibility.
John Haugeland is http://fullof.bs/
You can build an index by adding links in your markup, either using JavaScript in Prince or with some other scripting or transform language before the document is converted by Prince. However, there are still difficulties coalescing multiple references to identical page numbers, which we are still working on.
Please forgive the clunky code.
How can I access Prince-generated "content" using javascript?
How can I access Prince-generated "content" using javascript?
#glossary a[href]::after {
content: "," target-counter(attr(href), page);
}
function fixIndex()
{
for (var node = document.getElementById('glossary').firstChild; node; node = node.nextSibling)
{
if (node.nodeType == node.ELEMENT_NODE && node.className == "term")
{
for ( var link = node.firstChild; link; link = link.nextSibling)
{
if (link.nodeType == link.ELEMENT_NODE && link.tagName == "span")
{
console.log("Word: "+link.firstChild.nodeValue);
}
if (link.nodeType == link.ELEMENT_NODE && link.tagName == "a")
{
//console.log(" Link: "+link.attributes.getNamedItem("href").value); //firstChild.nodeValue);
console.log(" Link: "+link.firstChild.nodeValue; //firstChild.nodeValue);
}
}
}
}
}
Forgot to post that the page numbers are being generated appropriately.
I really want to gather the page numbers into an array and condense them using some string magic.
I really want to gather the page numbers into an array and condense them using some string magic.
Unfortunately you can't do this yet. Generated content does not show up in the DOM, and once document conversion is finished, JavaScript cannot trigger reconversion. We're still considering different ways of doing this.
Okay, here goes! 
You can make an index with a two-pass process. The first pass collects and saves the page numbers for all the index terms, and the second pass rewrites the index to use the page numbers collected in the first pass.
Here is a simple sample document, two pages talking about dogs and cats, and an index page at the end:
We can use CSS generated content and prince-script() to record the page numbers for all of the index links and print them out after formatting is complete, so they can be saved to a file. This requires some CSS and some JavaScript:
So for the first pass, run Prince like this:
This should generate a PDF file test.pdf that has the index including duplicated page numbers, eg. "Dogs: 1, 1, 2, 2" and also saves all the index page numbers to a JavaScript file out.js like this:
We can use these references to rewrite the index, run Prince again, and generate a PDF file without duplicated page numbers. This requires some more JavaScript:
And we run Prince like this:
Note that we are applying the script above and also the script that we generated while running the first pass, that contains the index page numbers. And if all goes well, that should generate a PDF where the index has "Dogs: 1, 2". Simple!
You can make an index with a two-pass process. The first pass collects and saves the page numbers for all the index terms, and the second pass rewrites the index to use the page numbers collected in the first pass.
Here is a simple sample document, two pages talking about dogs and cats, and an index page at the end:
<html>
<body>
<p>A paragraph about <span id="dog1">dogs</span>.</p>
<p>Another paragraph about <span id="dog2">dogs</span>.</p>
<p>A paragraph about <span id="cat1">cats</span>.</p>
<div style="page-break-before: always">
<p>A paragraph about <span id="dog3">dogs</span>.</p>
<p>Another paragraph about <span id="dog4">dogs</span>.</p>
<p>A paragraph about <span id="cat2">cats</span>.</p>
</div>
<div id="index" style="page-break-before: always">
Dogs:
<span class="refs">
<a href="#dog1">ref</a>,
<a href="#dog2">ref</a>,
<a href="#dog3">ref</a>,
<a href="#dog4">ref</a>
</span>
<br/>
Cats:
<span class="refs">
<a href="#cat1">ref</a>,
<a href="#cat2">ref</a>
</span>
</div>
</body>
</html>We can use CSS generated content and prince-script() to record the page numbers for all of the index links and print them out after formatting is complete, so they can be saved to a file. This requires some CSS and some JavaScript:
a[href] {
content: prince-script(index, attr(href), target-counter(attr(href), page))
}var refs = {};
function index(href, counter)
{
refs[href] = counter;
return counter;
}
function dumpIndex()
{
console.log("var refs = {");
var keys = [];
for (var href in refs)
{
keys.push(href);
}
keys.sort();
for (var i in keys)
{
var comma = (i < keys.length - 1 ? "," : "");
console.log("\""+keys[i]+"\": "+refs[keys[i]]+comma);
}
console.log("};");
}
Prince.addEventListener("complete", dumpIndex, false);
So for the first pass, run Prince like this:
prince --javascript --script pass1.js --style pass1.css test.html > out.jsThis should generate a PDF file test.pdf that has the index including duplicated page numbers, eg. "Dogs: 1, 1, 2, 2" and also saves all the index page numbers to a JavaScript file out.js like this:
var refs = {
"#cat1": 1,
"#cat2": 2,
"#dog1": 1,
"#dog2": 1,
"#dog3": 2,
"#dog4": 2
};We can use these references to rewrite the index, run Prince again, and generate a PDF file without duplicated page numbers. This requires some more JavaScript:
window.onload = rewriteIndex;
function rewriteIndex()
{
var div = document.getElementById("index");
var spans = div.getElementsByTagName("span");
for (var i = 0; i < spans.length; ++i)
{
var span = spans[i];
if (span.className == "refs")
{
//textContent property will be supported in Prince 8.1
//span.textContent = rewriteSpan(span);
setTextContent(span, rewriteSpan(span));
}
}
}
function rewriteSpan(span)
{
var text = "";
var lastPage;
var links = span.getElementsByTagName("a");
for (var i = 0; i < links.length; ++i)
{
var link = links[i];
var href = link.getAttribute("href");
if (!refs[href])
{
Log.warning("unknown index ref: "+href);
continue;
}
var page = refs[href];
if (text == "")
{
text = page;
lastPage = page;
}
else if (lastPage != page)
{
text += ", " + page;
lastPage = page;
}
}
return text;
}
function setTextContent(element, text)
{
while (element.firstChild)
{
element.removeChild(element.firstChild);
}
element.appendChild(document.createTextNode(text));
}
And we run Prince like this:
prince --script pass2.js --script out.js test.htmlNote that we are applying the script above and also the script that we generated while running the first pass, that contains the index page numbers. And if all goes well, that should generate a PDF where the index has "Dogs: 1, 2". Simple!
Congratulations! And how about
1,2,5-10,12
Can you add en-dash for contiguous page numbers?
1,2,5-10,12
Can you add en-dash for contiguous page numbers?
Jim Albright
Wycliffe Bible Translators
I love following your progress. Keep up the good work.
I still can't recommend using Prince for Bibles until inline footnotes and named footnote areas are allowed. But you ARE making progress towards that end. And along the way you are making lots of people happy with this high quality product. My needs are complex.
I still can't recommend using Prince for Bibles until inline footnotes and named footnote areas are allowed. But you ARE making progress towards that end. And along the way you are making lots of people happy with this high quality product. My needs are complex.
Jim Albright
Wycliffe Bible Translators
What was wrong with mine, which already collapsed ranges?
John Haugeland is http://fullof.bs/
I saw that your method removed duplicate entries. Does it also change
1,2,3,4,5 to
1-5
1,2,3,4,5 to
1-5
Jim Albright
Wycliffe Bible Translators
Maybe I should do the scan automation, too, so that it's fully automated like my ToC generator is.
John Haugeland is http://fullof.bs/
Just a quick tip. window.onload doesn't seem to work:
You can fix this by doing this:
window.onload = rewriteIndex;You can fix this by doing this:
addEventListener("load", rewriteIndex, false)
Another very important thing to note here is that if you copy this example directly and you have other "normal" links in the document, the page numbers will change from PDF 1 to PDF 2, because you're setting the content of all links (deleting the normal text of the link).
You probably want to wrap your index links in a div with "index" as id, and then change the css to this. That will fix it:
You probably want to wrap your index links in a div with "index" as id, and then change the css to this. That will fix it:
#index a[href] {
content: prince-script(index, attr(href), target-counter(attr(href), page));
}
Setting window.onload should work; can you try this simple test document:
<html>
<head>
<script>
function test() { alert("test function called") }
window.onload = test;
</script>
</head>
<body>
<p>Was test function called?</p>
</body>
</html>
Any way to pass in that out.js as a stream (as opposed to a file) to princely in the second pass? Doing it as a file is fine for one off, but in a server environment I don't like the idea of creating these temporary js files all the time.
Not yet, unless you include the JavaScript in the input HTML document itself, with a <script> tag.
I've managed to implement this in a single automatic pass, via a single content: prince-script(...) call.
The code is still very messy, and it does require the results for each "index word" to be numbered in an attribute - although this could probably be added as part of the script I guess.
I'll just post the output for now, and the code when I clean it up.
(Before and after shots of the same HTML)

Curious as to how it works? It takes advantage of the multiple pass processing to pre-index the entries before final output is rendered.
The code is still very messy, and it does require the results for each "index word" to be numbered in an attribute - although this could probably be added as part of the script I guess.
I'll just post the output for now, and the code when I clean it up.
(Before and after shots of the same HTML)
Curious as to how it works? It takes advantage of the multiple pass processing to pre-index the entries before final output is rendered.
I managed to wrangle it into shape, and remove the external requirements. Now it's plug and pray.
Regretfully I am too lazy to provide a sample document with indexes, but I have tested it with my own large (500 page) index document, and it works great.
This is the actual CSS from my project:
and this is the javascript, the incredibly un-minned version, made extra large by neatly wrapping it to 76 chars to fit in this window. (Good old RMIT 76 char standard line limit).
Regretfully I am too lazy to provide a sample document with indexes, but I have tested it with my own large (500 page) index document, and it works great.
This is the actual CSS from my project:
/* I have an especially complex, multi-tiered index. Your CSS
* should definately not looks as messed up as mine */
#index {
counter-reset: index-entry;
}
/* New word */
#index > ul > li > ul > li {
counter-reset: data-word-unique;
counter-increment: index-entry;
}
/* A page reference */
#index > ul > li > ul > li > ul > li > ul > li > a::after {
counter-increment: data-word-unique;
/* index-entry is the current word (or a counter), set using CSS
* data-word-unique is an incrementing CSS counter that resets
* for each word in the index.
*/
content: prince-script(getIndexNum, target-counter(attr(href), page), counter(index-entry), counter(data-word-unique));
}
and this is the javascript, the incredibly un-minned version, made extra large by neatly wrapping it to 76 chars to fit in this window. (Good old RMIT 76 char standard line limit).
// I stole these two functions from facebook. They're very handy if you
// don't happen to have a javascript library loaded.
function copy_properties(b, c) {
b = b || {};
c = c || {};
for (var a in c) b[a] = c[a];
if (c.hasOwnProperty && c.hasOwnProperty("toString")
&& typeof c.toString != "undefined"
&& b.toString !== c.toString)
b.toString = c.toString;
return b;
}
function add_properties(a, b) {
return copy_properties(window[a] || (window[a] = {}), b);
}
// Now we can extend the sfinktah object, if it already exists (e.g., if we
// used it for line numbering.)
sfinktah = add_properties(
(document.defaultView ? document.defaultView : window)
.sfinktah,
{
debug: false,
indexing: {
last: 0,
lastWord: 'antidisestablishmentarianism',
lastPage: 0,
start: 0,
output: '',
firstRunDone: false,
words: {},
},
getIndexNumSimple: function(page, word, word_ref_uniq) {
var maxxed = false; // This gets set to true when we
// at the last ref.
word_ref_uniq = Number(word_ref_uniq);
page = Number(page); // Thanks mikeday, I would still
// be using parseInt(s, 10) !!!!
if (!(word in sfinktah.indexing.words)) {
sfinktah.indexing.words[word] = { max: -1, words: [] };
}
if (page === sfinktah.indexing.words[word].words[word_ref_uniq]) {
sfinktah.indexing.firstRunDone = true;
}
// Record page numbers for each word, indexed by
// word_ref_uniq so it cleanly overwrites each
// pass.
sfinktah.indexing.words[word].words[word_ref_uniq] = page;
// Check if we are at the last word (this will
// be true a lot during the first pass, but
// no matter).
if ( word_ref_uniq >= sfinktah.indexing.words[word].max ) {
maxxed = true;
sfinktah.indexing.words[word].max = word_ref_uniq;
}
if (sfinktah.debug)
Prince.Log.info('page: ' + page + ' word: ' + word + ' max: '
+ sfinktah.indexing.words[word].max + ' word_ref_uniq: '
+ word_ref_uniq);
// Reset state after switching to next word
if (word != sfinktah.indexing.lastWord) {
sfinktah.indexing.lastWord = word;
sfinktah.indexing.lastPage = 0;
}
// If we have a new page number, (or if there are
// duplicate last pages and this is the last)
if (maxxed || page != sfinktah.indexing.lastPage) {
sfinktah.indexing.lastPage = page;
// TOOD: We need not run this for the first
// pass, but it doesn't hurt us.
if (maxxed) {
sfinktah.indexing.last = sfinktah.indexing.start = 0;
sfinktah.indexing.output = '';
// Iterate through all known page refs (this
// assumes they they're already sorted)...
sfinktah.indexing.words[word].words.forEach( function( v ) {
var $page = Number(v);
if ($page == sfinktah.indexing.last) {
return;
}
// The range compaction code is hard to explain,
// mainly beacuse I didn't comment when I wrote it
// two years ago. I'll document the featury bits.
// This creates or extends a range, allowing a 1
// page gap (eg, 1,2,4,5 becomes 1--5). If you feel
// the need to be Honest Joe about it, remove the
// page == last + 2.
if (sfinktah.indexing.last > 0
&& (
$page == sfinktah.indexing.last + 1
|| $page == sfinktah.indexing.last + 2
)
) {
sfinktah.indexing.start = sfinktah.indexing.start
? sfinktah.indexing.start
: sfinktah.indexing.last;
sfinktah.indexing.last = $page;
return;
}
if (sfinktah.indexing.start) {
if (sfinktah.indexing.last
- sfinktah.indexing.start > 0) {
// This is an endash. If you don't know what
// or why, you have no job making an index in
// the first place.
sfinktah.indexing.output
+= String.fromCharCode(0x2013)
+ sfinktah.indexing.last;
sfinktah.indexing.start = 0;
} else {
// This may never be reached under normal
// operation, so if you see a "..," appear in
// your index, let me know. :) sfinktah@
// princexml.spamtrak.org
sfinktah.indexing.output += ".., "
+ sfinktah.indexing.last;
sfinktah.indexing.start = 0;
}
}
if (sfinktah.indexing.output.length) {
sfinktah.indexing.output += ", ";
}
sfinktah.indexing.output += $page;
sfinktah.indexing.last = $page;
// I told you it was black magic. Just be greatful
// that I left all excess braces in, and didn't
// run it through the Google Closure compiler...
// ... hmm, although it is tempting...
});
// If we were counting out a range, then it's over now.
if (sfinktah.indexing.start) {
sfinktah.indexing.output += String.fromCharCode(0x2013)
+ sfinktah.indexing.last;
}
return sfinktah.indexing.output;
}
}
// If we have reached this point, we're in one of the three
// passes that princexml performs. Those passes seem to be:
//
// (1) Run through all the references, with the page number
// set to 1 (except when it's set to 0 -- don't ask me)
//
// (2) Second run through all the references, but with page
// numbers, which have been devined from pass 1.
//
// (3) Third run, which happens after "Resolving cross-
// references..." I couldn't explain exactly what this
// pass does, but it would have something to do with
// adjusting paging and numbering again, to accomodate
// changes in CSS derived dynamic content, which might
// shift things around a little. And I guess it's quite
// possible, that princexml didn't actually know all
// the correct page numbers during the second run.
//
// The good new is, that we don't rely on knowing which pass
// we are in, or even how many passes there are. We try to
// flow as dynamically as possible.
//
// It's quite likely that we output some really crazy stuff
// during the first pass, but everything appears to work out
// in the end. There were some problems with truncated lines,
// but some of the quick hacks like firstRunComplete probably
// fixed those.
//
// So - if somehow we are reaching here during 1st pass, then we
// output a normal page number. Otherwise, we output a
// compressed range.
// Importantly, no matter what phase does what, we are hopefully
// outputing at least the minimum amount of data to ensure there
// is enough room for our index.
return sfinktah.indexing.firstRunDone ? '' : (page + ', ');
},
});
// Now to define our exports
Prince.addScriptFunc("getIndexNum", function(page, word, word_ref_uniq) {
return sfinktah.getIndexNumSimple(page, word, word_ref_uniq);
});
And, for comparison, here is the closure compiled version (still functional) and still wrapped to 76 chars for.... readability?
var d = window.k, e = window[d] || (window[d] = {}), g = {debug:!1, a:{d:0,
g:"antidisestablishmentarianism", e:0, start:0, b:"", f:!1, c:{}},
h:function(b, a, c) {
var f = !1;
c = Number(c);
b = Number(b);
a in sfinktah.a.c || (sfinktah.a.c[a] = {max:-1, c:[]});
b === sfinktah.a.c[a].c[c] && (sfinktah.a.f = !0);
sfinktah.a.c[a].c[c] = b;
c >= sfinktah.a.c[a].max && (f = !0, sfinktah.a.c[a].max = c);
a != sfinktah.a.g && (sfinktah.a.g = a, sfinktah.a.e = 0);
if (f || b != sfinktah.a.e) {
if (sfinktah.a.e = b, f) {
return sfinktah.a.d = sfinktah.a.start = 0, sfinktah.a.b = "",
sfinktah.a.c[a].c.forEach(function(a) {
a = Number(a);
a != sfinktah.a.d && (0 < sfinktah.a.d && (a == sfinktah.a.d + 1 ||
a == sfinktah.a.d + 2) ? sfinktah.a.start = sfinktah.a.start
? sfinktah.a.start : sfinktah.a.d : (sfinktah.a.start &&
(sfinktah.a.b = 0 < sfinktah.a.d - sfinktah.a.start
? sfinktah.a.b + (String.fromCharCode(8211) + sfinktah.a.d)
: sfinktah.a.b + (".., " + sfinktah.a.d), sfinktah.a.start
= 0), sfinktah.a.b.length && (sfinktah.a.b += ", "),
sfinktah.a.b += a), sfinktah.a.d = a);
}), sfinktah.a.start && (sfinktah.a.b += String.fromCharCode(8211)
+ sfinktah.a.d), sfinktah.a.b;
}
}
return sfinktah.a.f ? "" : b + ", ";
}}, e = e || {}, g = g || {}, h;
for (h in g) {
e[h] = g[h];
}
g.hasOwnProperty && g.hasOwnProperty("toString") && "undefined" != typeof
g.toString && e.toString !== g.toString && (e.toString = g.toString);
sfinktah = e;
Prince.addScriptFunc("getIndexNum", function(b, a, c) {
return sfinktah.h(b, a, c);
});
Edited by sfinktah
That's very clever, and I may even vaguely understand how it works.
Is there any way we can make this process easier, or is it already sufficiently simple?
Is there any way we can make this process easier, or is it already sufficiently simple?
Funny you should ask, I just got through writing some nasty little code to automatically index a document – to use as a complete example.
However, it doesn't run under prince... and not for any of the reasons I would have suspected. It appears to have something to do arrays and objects.
edit: in retrospect it was obviously unwise to assume that prince supported the .textContent property. from now on, i'll just pretend i'm coding for internet explorer.
However, it doesn't run under prince... and not for any of the reasons I would have suspected. It appears to have something to do arrays and objects.
edit: in retrospect it was obviously unwise to assume that prince supported the .textContent property. from now on, i'll just pretend i'm coding for internet explorer.
Edited by sfinktah

Index created entirely within Prince. Not necessarily easier to use, but certainly more impressive.
prince --javascript http://nt4.com/nm.html --script http://nt4.com/msn-index.js -vo nm.pdf && open nm.pdf
It shouldn't be hard to write it as a jQuery extension, if that's what you had in mind as 'easy to use'.
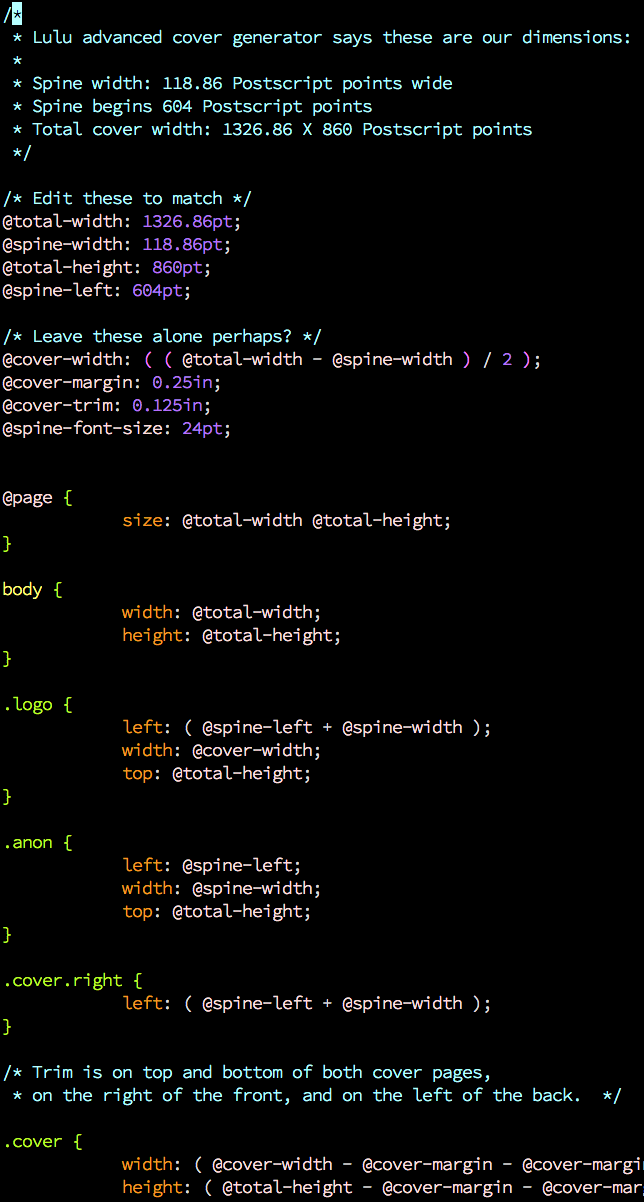
Although, it we're going to hold their hands that tight, we'll have to throw in the automatic cover generator too - and the javascript in that does not play nicely with Prince. (lesscss.org)

You've certainly got a lot going on! But Prince does support the textContent DOM property, or at least it should. How was it failing exactly?
I believe it was returning undefined. I've been going through lesscss.org's engine, trying to fix it for 'prince compliance', so if you want an addition list:
prince doesn't support bind (I used a polyfill), and doesn't support the .ref or .type properties of a HTMLLinkElement, (I replaced them with links[i].attributes[rel] and so forth.
That's gotten me this far:
Got a replacement for window.location.href? (I guess it would be the path / URL of the document prince was currently processing). I can probably flub it into a working state, but then it would fail on remote URLs. And I like using URLs on the command line.
Also, I rewrote my indexer. Now it uses dl, dt and dd, which will make the CSS and user involvement for the prince-indexer (that's wholly separate from the indexer) much easier. Code is up on http://nt4.com/nm2.js.
Oh BTW, what I've done can already index (and then prince-index) an arbitrary web page... eg:
Will produce a rather hideous, but indexed, copy of the PrinceXML javascript doc page.
prince doesn't support bind (I used a polyfill), and doesn't support the .ref or .type properties of a HTMLLinkElement, (I replaced them with links[i].attributes[rel] and so forth.
That's gotten me this far:
extractUrlParts(originalHref, window.location.href);
Got a replacement for window.location.href? (I guess it would be the path / URL of the document prince was currently processing). I can probably flub it into a working state, but then it would fail on remote URLs. And I like using URLs on the command line.
Also, I rewrote my indexer. Now it uses dl, dt and dd, which will make the CSS and user involvement for the prince-indexer (that's wholly separate from the indexer) much easier. Code is up on http://nt4.com/nm2.js.
Oh BTW, what I've done can already index (and then prince-index) an arbitrary web page... eg:
prince --script http://nt4.com/js/jquery --script http://nt4.com/js/jquery.highlight --script http://nt4.com/js/jquery.tinysort --script http://nt4.com/js/underscore --script http://nt4.com/nm.js --script http://nt4.com/msn-index.js http://www.princexml.com/doc/9.0/javascript/ -s http://nt4.com/nm.css -vo t.pdf
Will produce a rather hideous, but indexed, copy of the PrinceXML javascript doc page.
Okay, textContent should definitely be returning either a string or null, so please let me know if you can narrow down a specific test case where you have a node where the property isn't working.
I'll add the HTMLLinkElement special properties to the roadmap for implementation.
Regarding window.location.href, which version of Prince are you using? This property has been supported for some time. Perhaps it is being overwritten?
I'll add the HTMLLinkElement special properties to the roadmap for implementation.
Regarding window.location.href, which version of Prince are you using? This property has been supported for some time. Perhaps it is being overwritten?
ahh, my bad. Despite doing my research, I somehow used [b]innerText[b] instead of textContent.
and you are also probably correct about window.location.href. I had 3 or 4 potential callee to a problem spot, and no way do to a stack track - window.location.href just looked like it was the obvious culprit. (Turned out to be another HTMLLinkElement property .href 3 functions up).
and you are also probably correct about window.location.href. I had 3 or 4 potential callee to a problem spot, and no way do to a stack track - window.location.href just looked like it was the obvious culprit. (Turned out to be another HTMLLinkElement property .href 3 functions up).
Add in xhr.getResponseHeader (After an XHR request) to the undefined list, and that's it... for less.js anyway.
Of course, it doesn't actually work. But there are no errors. After trying to track it down for a while, I thought it might be wise to write a polyfill for the missing HTMLLinkElement properties...
Turns out, HTMLLinkElement didn't exist, neither did HTMLElement. That was too confusing for me, so I stopped for the night. Next time I'll just use a regex on the source code.
Of course, it doesn't actually work. But there are no errors. After trying to track it down for a while, I thought it might be wise to write a polyfill for the missing HTMLLinkElement properties...
["rel", "type", "href"].forEach( function(p) {
try {
// Both version throw an exception:
// defineProperty Exception: TypeError: undefined value is not an object
// Object.defineProperty(HTMLLinkElement.prototype, p, { get: function() { return this.getAttribute(p); }} );
Object.defineProperty(HTMLLinkElement.prototype, p, { get: function() { return this.attributes[p] && this.attributes[p].value; }} );
} catch (e) {
console.log('defineProperty Exception: ' + e);
}
});
Turns out, HTMLLinkElement didn't exist, neither did HTMLElement. That was too confusing for me, so I stopped for the night. Next time I'll just use a regex on the source code.
Right, Prince is missing the HTMLElement interfaces, and just has the base DOM interfaces like Node, Element, etc. We will add HTMLLinkElement and others in the next release.
Yeah, I coded around it, and around the missing JSON object too
Got a chapter-splitting solution working too...
And a lot of javascript and shell scripting that is way too large to paste.
The end result - your PDF is split into xyz-chapter01.pdf ... xyz-chapter-99.pdf. Then you can join the bits to make up each volume. It's hard to split a PDF in exactly the right spot, but its easy to join up a bunch of PDF's ☺
And you can define pages to insert infront, like the copyright and book title... "pdfjam" lovely stuff. I'll post it up when I have it checked it more thoroughly.
Got a chapter-splitting solution working too...
body > :first-child {
/* We need to reset this counter each time around */
counter-reset: chapter-count 0;
}
body > div::before {
/* This just captures oddities such as front matter,
/* and to be an example. You'll have to add the same
* CSS properties to whatever selector marks your
* chapters (or whatever you are trying to split) */
counter-increment: chapter-count;
content: prince-script(newChapter, counter(page), counter(chapter-count));
}
div.book > div.chapter::before {
counter-increment: chapter-count;
content: prince-script(newChapter, counter(page), counter(chapter-count));
}
...
chapter 43 page 2009
chapter 43 page 2009
chapter 44 page 2025
chapter 44 page 2025
prince: JSON: [object Object]
prince: JSON.stringify: <<function>>
prince: @@CHAPTERS: chapters=( "65..78" "79..224" "225..228" "229..230" "231..232" "233..258" "259..296" "297..332" "333..334" "335..376" "377..412" "413..444" "445..510" "511..624" "625..700" "701..702" "703..836" "837..850" "851..878" "879..898" "899..912" "913..916" "917..934" "935..996" "997..998" "999..1084" "1085..1090" "1091..1098" "1099..1110" "1111..1128" "1129..1132" "1133..1134" "1135..1202" "1203..1246" "1247..1288" "1289..1400" "1401..1442" "1443..1600" "1601..1824" "1825..1976" "1977..1996" "1997..2008" "2009..2024" "2025..2042")
prince: Finished: success
And a lot of javascript and shell scripting that is way too large to paste.
The end result - your PDF is split into xyz-chapter01.pdf ... xyz-chapter-99.pdf. Then you can join the bits to make up each volume. It's hard to split a PDF in exactly the right spot, but its easy to join up a bunch of PDF's ☺
And you can define pages to insert infront, like the copyright and book title... "pdfjam" lovely stuff. I'll post it up when I have it checked it more thoroughly.
Hmmm... I seem to have broken prince with a 2,048 page document. Although, it only breaks when running my splitting plugin. It was working yesterday about 70% of the time, but now it's not working at all. That is, it's hangs somewhere toward the end of the 3rd (I think) pass of Resolving References, at about page 1800.
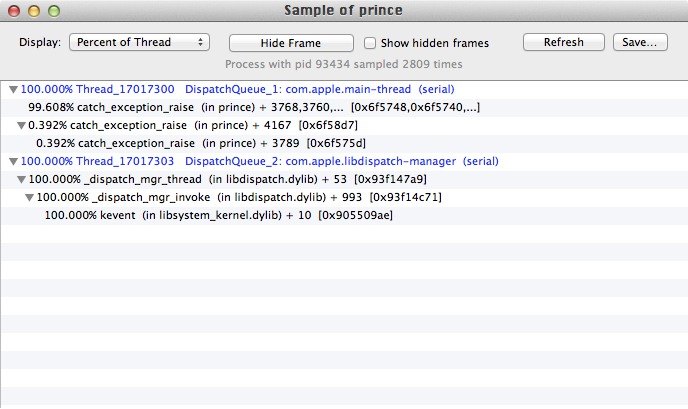
Could you possibly run this and confirm/diagnose?
The chapter splitting script is up there too, if you do get it to work and are curious: http://nt4.com/jcv/jcv-split-chapters.sh
Could you possibly run this and confirm/diagnose?
prince http://nt4.com/jcv/jcv_vsm.html -vo jcv_vsm.pdf --script http://nt4.com/jcv/jcv-chapters.js -s http://nt4.com/jcv/jcv-chapters.css
The chapter splitting script is up there too, if you do get it to work and are curious: http://nt4.com/jcv/jcv-split-chapters.sh