Version: Prince 10 rev 2
In our PDF, we use a font family consist of 6 styles, each with individual font file.
Currently, when embedding the fonts, PrinceXML will use the Preferred Family name with style appended.
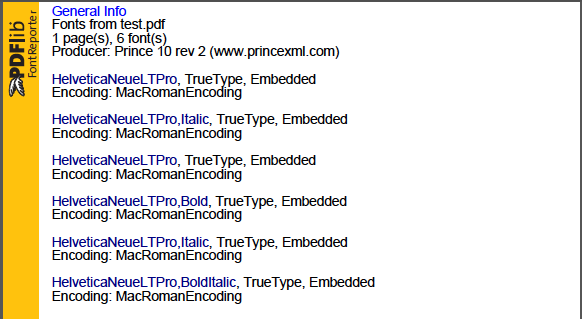
However, the embedded name does not seems to capture the light family as part of the style, which means, there the light and normal style are using the same name but representing different font style. This is potentially making the font indistinguishable to our print vendor's post-process software, causing printing issue.
Is there a way to change PrinceXML's font embedding behavior to include the PostScript name instead?
Also, the font will be encoded in MacRomanEncoding or built-in or Identity-H. Depending on the usage of non-BMP characters and the --no-subset-fonts option.
It there a way to force a single encoding?
In our PDF, we use a font family consist of 6 styles, each with individual font file.
- light
- light italic
- normal
- bold
- italic
- bold italic
Currently, when embedding the fonts, PrinceXML will use the Preferred Family name with style appended.
However, the embedded name does not seems to capture the light family as part of the style, which means, there the light and normal style are using the same name but representing different font style. This is potentially making the font indistinguishable to our print vendor's post-process software, causing printing issue.
Is there a way to change PrinceXML's font embedding behavior to include the PostScript name instead?
Also, the font will be encoded in MacRomanEncoding or built-in or Identity-H. Depending on the usage of non-BMP characters and the --no-subset-fonts option.
It there a way to force a single encoding?
Edited by yiqiu
